| Pages in topic: [1 2] > |
Looking for properly aligned TMXs of the European Medicines Agency (EMEA) corpus! (DutchEnglish) Thread poster: Michael Beijer
|
|---|
Michael Beijer 
United Kingdom
Local time: 02:06
Member (2009)
Dutch to English
+ ...
Every once in a while I will look stuff up in my EMEA.tmx (which I downloaded via the OPUS corpus a while ago)(http://opus.lingfil.uu.se/EMEA.php … now offline), and although it is full of very useful info, it also contains a vast amount of misalignments, which makes it annoying to use for concordance purposes. I haven't had time lately to look into whether anyone has managed to get their hands on a ... See more Every once in a while I will look stuff up in my EMEA.tmx (which I downloaded via the OPUS corpus a while ago)(http://opus.lingfil.uu.se/EMEA.php … now offline), and although it is full of very useful info, it also contains a vast amount of misalignments, which makes it annoying to use for concordance purposes. I haven't had time lately to look into whether anyone has managed to get their hands on a properly aligned version. Have you?
I am specifically interested in the Dutch English part of the corpus.
Michael
(For future googlers) this is where I found it:
http://opus.lingfil.uu.se -> EMEA - European Medicines Agency documents (EMEA0.3.tar.gz - 5.0 GB) -> http://opus.lingfil.uu.se/EMEA.php
[Edited at 2017-09-27 10:10 GMT] ▲ Collapse
| | | |
CafeTran Training (X)
Netherlands
Local time: 03:06
Michael Joseph Wdowiak Beijer wrote: Every once in a while I will look stuff up in my EMEA.tmx (which I downloaded via the OPUS corpus a while ago)( http://opus.lingfil.uu.se/EMEA.php … now offline), Michael
Aren't these also harvested by Linguee and offered by DeepL?
| | | |
Michael Beijer
United Kingdom
Local time: 02:06
Member (2009)
Dutch to English
+ ...
TOPIC STARTER | I would expect so, but... | Sep 27, 2017 |
CafeTran Training wrote: Michael Joseph Wdowiak Beijer wrote: Every once in a while I will look stuff up in my EMEA.tmx (which I downloaded via the OPUS corpus a while ago)( http://opus.lingfil.uu.se/EMEA.php … now offline), Michael Aren't these also harvested by Linguee and offered by DeepL?
I just did a quick check, and it seems that they aren't. I mean, I'm sure that they have found them and that they are part of their system, somehow, but when you take a specific source segment from one of the EMEA TMXs, both Linguee and DeepL produce different results. This usually wouldn't be such a problem, but when I am translating stuff like medicine inserts/leaflets, I need to stick to extremely specific terminology, some of which is present in the specialized medical TMXs.
By the way, have you tried using CafeTran yet as a TMX cleaner, for stuff like: 1. Remove any TU with either side = longer than the other, 2. Remove any TU that is etc.?
| | | |
I could look into cleaning it up or repeating the alignment from scratch.
What problems are you seeing and how bad is it? I don't think I even downloaded the EMEA corpus so all I know about it is that it is available.
I have a tool that removes TUs where one side is X% longer/shorter than the other. That can help remove most of the misaligned stuff. Just "longer" is not good as a criterion as one side is always bound to be a bit longer than the other. Removing very long (and v... See more I could look into cleaning it up or repeating the alignment from scratch.
What problems are you seeing and how bad is it? I don't think I even downloaded the EMEA corpus so all I know about it is that it is available.
I have a tool that removes TUs where one side is X% longer/shorter than the other. That can help remove most of the misaligned stuff. Just "longer" is not good as a criterion as one side is always bound to be a bit longer than the other. Removing very long (and very short) segments can also be useful.
[Edited at 2017-09-27 10:10 GMT] ▲ Collapse
| | |
|
|
|
CafeTran Training (X)
Netherlands
Local time: 03:06
| It's a feature that I miss, however .... | Sep 27, 2017 |
Michael Joseph Wdowiak Beijer wrote:
By the way, have you tried using CafeTran yet as a TMX cleaner, for stuff like: 1. Remove any TU with either side = longer than the other, 2. Remove any TU that is etc.?
It's a feature that I miss, but it's very unlikely that it'll get implemented ever. The developer today announced that he's thinking about 'refactoring' CafeTran (just like Kilgray did some time ago), in order to reduce its complexity. This can have consequences for CafeTran's feature set.
New feature's are only likely to get added in future, when they reduce CafeTran's complexity/simplify its operation/GUI and make it more intuitive/easy to understand.
| | | |
Michael Beijer
United Kingdom
Local time: 02:06
Member (2009)
Dutch to English
+ ...
TOPIC STARTER | the heat is on! | Sep 27, 2017 |
CafeTran Training wrote: Michael Joseph Wdowiak Beijer wrote:
By the way, have you tried using CafeTran yet as a TMX cleaner, for stuff like: 1. Remove any TU with either side = longer than the other, 2. Remove any TU that is etc.? It's a feature that I miss, but it's very unlikely that it'll get implemented ever. The developer today announced that he's thinking about 'refactoring' CafeTran (just like Kilgray did some time ago), in order to reduce its complexity. This can have consequences for CafeTran's feature set. New feature's are only likely to get added in future, when they reduce CafeTran's complexity/simplify its operation/GUI and make it more intuitive/easy to understand.
Have you seen this? https://www.proz.com/forum/déj��_vu_support/319028-come_check_out_our_new_website.html (forum software broke the link, but you get the picture)
After months of hard work, we are proud to announce the launch of our new website!
The design has been improved to achieve a more modern and fresh look, and enhance the user experience .
Check it out, it's here: https://atril.com/
Expect intuitive navigation, easy access to our products and a wealth of valuable tips and resources.
We have also optimized it for smartphones and tablets to make it easier for you to access it wherever you are.
And there’s more to come!
The new DVX4, packed up with exciting new features, is just around the corner!
Go to the website and click the red X4 button to stay in the know.
Tell us what you think!
kind regards,
Matylda
Has the sleeping giant finally woken?
| | | |
Michael Beijer
United Kingdom
Local time: 02:06
Member (2009)
Dutch to English
+ ...
TOPIC STARTER | it's this one! | Sep 27, 2017 |
FarkasAndras wrote:
I could look into cleaning it up or repeating the alignment from scratch.
What problems are you seeing and how bad is it? I don't think I even downloaded the EMEA corpus so all I know about it is that it is available.
I have a tool that removes TUs where one side is X% longer/shorter than the other. That can help remove most of the misaligned stuff. Just "longer" is not good as a criterion as one side is always bound to be a bit longer than the other. Removing very long (and very short) segments can also be useful.
[Edited at 2017-09-27 10:10 GMT]
Thanks!
src/trgt files separate: http://opus.lingfil.uu.se/download.php?f=EMEA/en-nl.txt.zip
tmx: http://opus.lingfil.uu.se/download.php?f=EMEA/en-nl.tmx.gz
Michael
| | | |
CafeTran Training (X)
Netherlands
Local time: 03:06
FarkasAndras wrote:
I have a tool that removes TUs where one side is X% longer/shorter than the other. That can help remove most of the misaligned stuff. Just "longer" is not good as a criterion as one side is always bound to be a bit longer than the other. Removing very long (and very short) segments can also be useful.
[Edited at 2017-09-27 10:10 GMT]
Would you be willing to make this useful tool publicly available?
| | |
|
|
|
CafeTran Training wrote: FarkasAndras wrote:
I have a tool that removes TUs where one side is X% longer/shorter than the other. That can help remove most of the misaligned stuff. Just "longer" is not good as a criterion as one side is always bound to be a bit longer than the other. Removing very long (and very short) segments can also be useful.
[Edited at 2017-09-27 10:10 GMT] Would you be willing to make this useful tool publicly available?
It's part of the secret sauce I'm offering for people who want to buy TMs from me. As implemented, it's not very user friendly anyway.
BTW programming-wise, it's a trivial problem to solve:
if (length a) > (length b) * X then remove unit
if (length b) > (length a) * X then remove unit
I ended up using the formula if (length a) > ((length b) + 5) * 2 but you can always play with that.
| | | |
FarkasAndras wrote:
What problems are you seeing and how bad is it?
Also, are you willing to pay for getting it fixed*? If it's trivial I'll do it for free but not if it takes hours or days.
*Obviously it will never be perfect but perhaps it's possible to make it much better than it is now.
| | | |
Michael Beijer
United Kingdom
Local time: 02:06
Member (2009)
Dutch to English
+ ...
TOPIC STARTER | sorry, wasn't clear | Sep 27, 2017 |
FarkasAndras wrote: FarkasAndras wrote:
What problems are you seeing and how bad is it? Also, are you willing to pay for getting it fixed*? If it's trivial I'll do it for free but not if it takes hours or days. *Obviously it will never be perfect but perhaps it's possible to make it much better than it is now.
Yes, I'd be willing to pay something for it. Not too much though (if it's too much work just drop it), as I only use it occasionally.
Michael
| | | |
Emma Goldsmith
Spain
Local time: 03:06
Member (2004)
Spanish to English
| I'm interested... | Sep 27, 2017 |
... to hear the outcome of Andras' alignment of the EN-NL EMEA corpus.
The automatic alignment is very poor; I just use the tmx for concordance.
The other problem with the EMEA corpus is that it hasn't been updated since 2009 (as its name suggests).
| | |
|
|
|
So, what are the problems? With a few typical examples if possible. Just misalignments?
Also, what documents are included in the TM? If there's interest I could look into collecting the newer documents.
| | | |
Michael Beijer
United Kingdom
Local time: 02:06
Member (2009)
Dutch to English
+ ...
TOPIC STARTER | a few example of misalignments | Sep 28, 2017 |
Here are a few examples of the misalignments I am talking about:
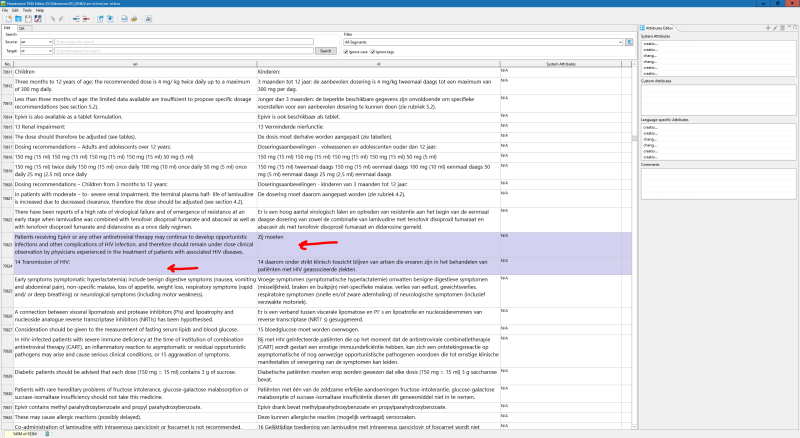
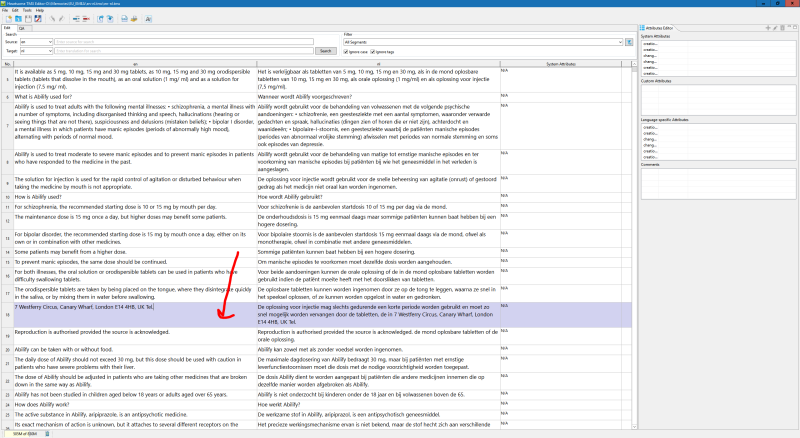
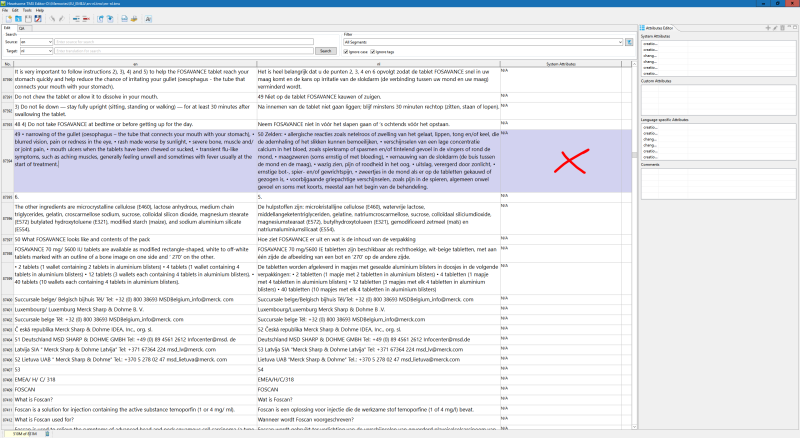
I'm not sure which documents are included in the TM, I'm not much of a medical specialist, maybe someone else in this thread knows? Emma? I know you specialise in medical stuff.
| | | |
Emma Goldsmith
Spain
Local time: 03:06
Member (2004)
Spanish to English
| Content of EMEA corpus | Feb 28, 2018 |
The corpus contains all EPARs (European public assessment reports) of centrally authorised medicines in the EU.
Each EPAR contains a summary, assessment history, summary of product characteristics, package leaflet and labelling for a medicine.
The only way to update the corpus (which runs to 2009 at present) would be to manually download all the EPARs from the EMA website - a mammoth undertaking.
Apologies for the 6-month delay answering, Michael ... See more ... See more The corpus contains all EPARs (European public assessment reports) of centrally authorised medicines in the EU.
Each EPAR contains a summary, assessment history, summary of product characteristics, package leaflet and labelling for a medicine.
The only way to update the corpus (which runs to 2009 at present) would be to manually download all the EPARs from the EMA website - a mammoth undertaking.
Apologies for the 6-month delay answering, Michael ▲ Collapse
| | | |
| Pages in topic: [1 2] > |





